
こんにちは。ヒデモです。
前回はPowerShell的な使い方が多かったので、改めてRAPっぽくWEBブラウザ操作をしてみました。
せっかくなので、WEBニュースを閲覧する時に遭遇する「もっと見る」を自動回避してみます。
「Power Automate Desktop」のインストール方法と簡単なフローはこちらの記事をご覧ください。
試すこと
MSNの総合TOPニュースを閲覧
「もっと見る」のクリックを自動化し、記事全文を閲覧
ニュースのHTMLソースを取得
記事全文をテキストファイル化
ニュースの一部を画像化
フロー作成してみる
1.最初はブラウザ起動する
早速、試したいことをもとにWEB操作を行ってみます。
表示したいサイトURLを張り付けます。今回はMSNのTOPページを指定しています。

2.総合TOPの記事をクリックさせる
MSNのTOPページの左上、総合ニュースに画像付きで表示されるトピックニュースをクリックさせましょう。
まず「WEBページのリンクをクリックします」を選択すると以下のような画面がでます。
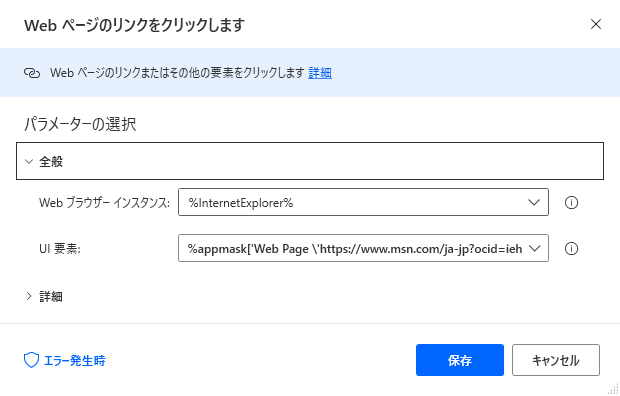
UI要素をクリックすると、「新しいUI要素の追加」ができるので、これを使ってUIを取得します。
ちなみにフロー作成画面の右端にあるアイコン「UI追加」からでも同様にUIの取得ができます。
※初見じゃわかりくい場所にあります。
「追跡セッション」が開いている状態で、UI要素にマウスカーソルをあてると”<p>”のようにタグ名が赤枠で表示されます。この状態で、赤枠をCTRL押しながら左クリックでUIを追加できます。
説明には左矢印も同時に押してと記載がありますが、押さなくて大丈夫です。(おそらく誤訳でしょう

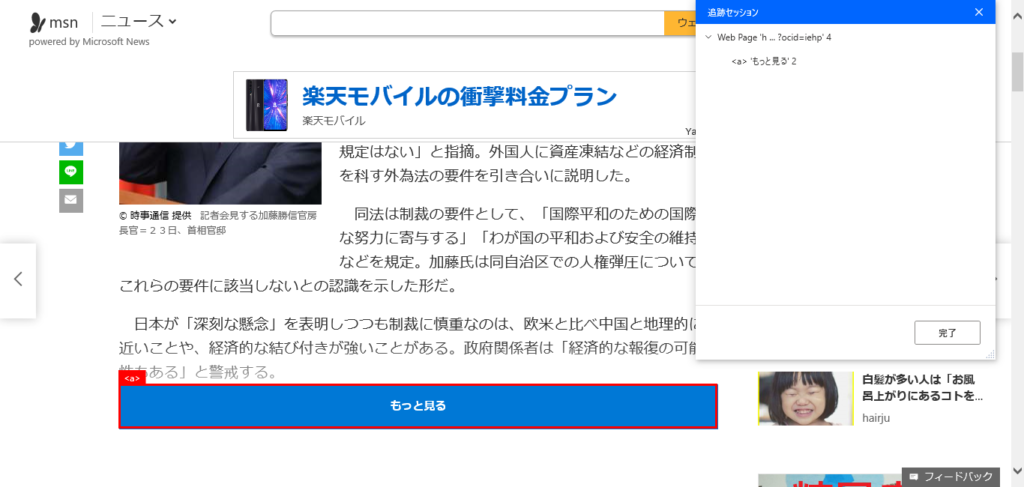
3.「もっと見る」をクリックさせる
※記事全文を取得するだけなら、実は不要でした。画像化する際に「もっと見る」があると格好が悪いので残しています。
WEBニュースのあるある「もっと見る」、鬱陶しいので自動化させちゃいましょう。
同じようにマウスカーソルを当てて、UIを取得します。
4.すべての記事内容を取得する
次は記事内容をテキストで抽出してみます。
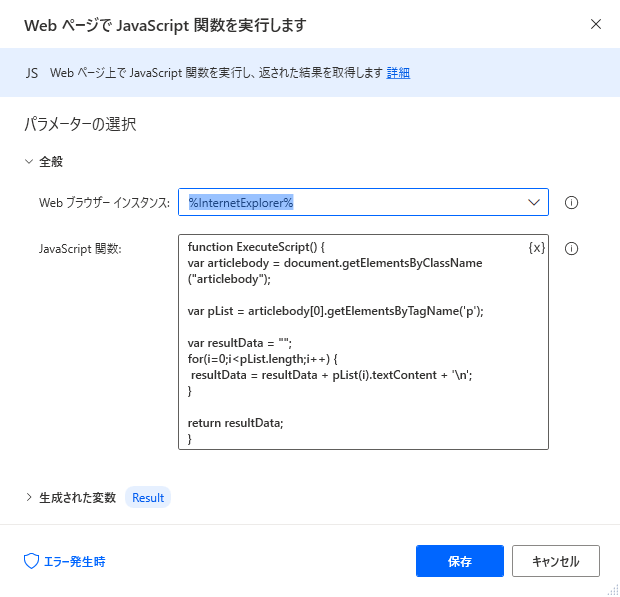
使ったアクションは「WebページでJavaScript関数を実行する」です。
※本当は用意されているアクションでやりたかったのですが、出来なかったのでJavaScriptでごり押ししました。
記事を解析すると、”articlebody”要素の中に、複数の”p”要素があることがわかりました。
“p”つまり、段落ごとに記事がかかれているのですね。
ここまでくればあとは”p”をまとめて取得して、中身のテキストを抽出するだけです。
↓がこれらを実現している処理。
5.記事のソースを取得する
ソースの取得は「Webページ上の詳細を取得する」でできました。非常にシンプルです。
ソース解析も組み合わせることで、WEBスクレイピングも可能です。

6.記事を画像化する
画面キャプチャを取得するアクション「Webページのスクリーンショットを取得します」でやりました。
今まで同様に、取得したいUIを選択させます。選択範囲が画像化できると思えばOKです。

7.できあがり
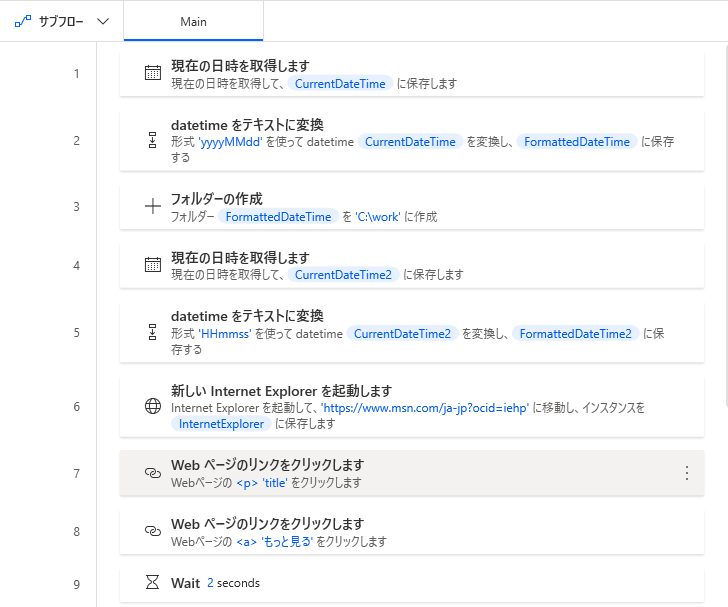
今まで作ったアクションで、下のフローが完成します。
PCスペックに依存しますが、ページ反映が遅いので「もっと見る」の後に、待機時間を追加しています。

OUTPUTはこんな感じです。


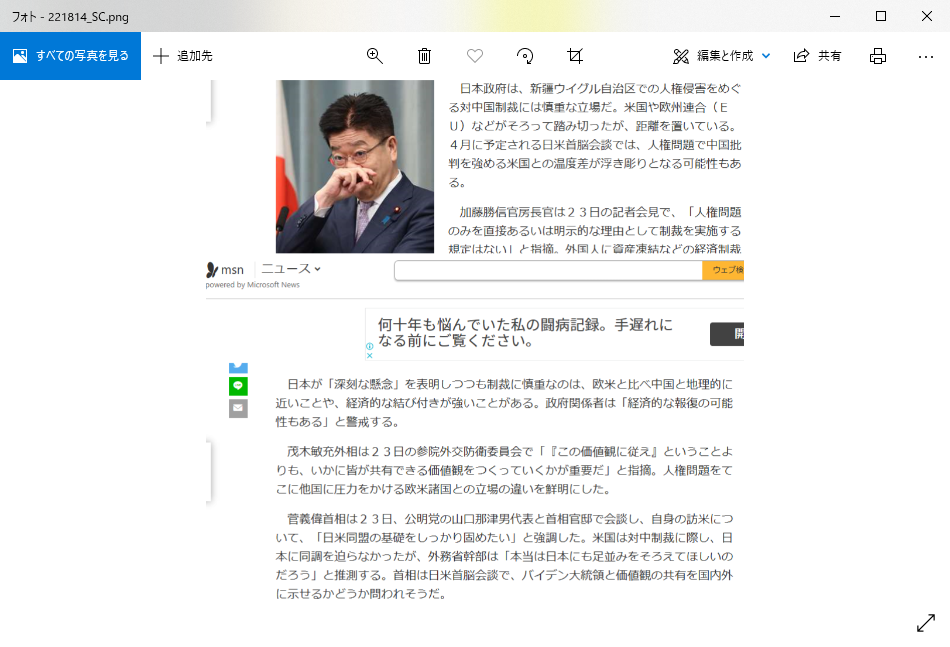
やってみてわかったこと
1.低スペックPCだと動作がもっさりでストレス溜まる
6年程度前のノートPC(メモリ4Gib、CPU i5-4200)なので、検証PC性能が悪いせいもあるのですが。全体的にもっさりしています。特にHTML UI要素取得の動作が遅く、
近年発売しているPCであれば問題ないと思いますので、古いPCでの使い方は推奨しません。
2.HTML UI要素の取得が難しい
実際にやってみるとわかりますが、少しずれるだけでUI取得できなくなります。
これが非常にストレスで”a”タグを取得したいのに、”div”が反応することもあります。
UI要素の取得動作は、改善してほしいですね。
出来なかったこと
1.IE以外のブラウザでWEB操作
これさっぱりわからないのですが、ChromeでIEと同様な手順を踏んでもUI要素が取得できないのです。
こんなかんじにUI取得できているようにみえますが、これは失敗です。IEでも起こることがあります。
“a”としてUI取得したいのに、”HyperLink”として認識されている気がしますね。
Chromeでもできたよー!!って方、是非やり方を教えてください。

2.要素内にある複数の要素を取得できない
今回はJavaScriptでごり押ししましたが、ほかにいい方法ないのでしょうか?
「WEBページからデータを抽出する」で取得できそうなのですが…
ウィンドウ後ろのWEBページみてもわかるように、”p”タグが点線で囲まれています。
ぱっとみできてるように見えますが、実際に動かすと何も取得できていませんでした。

今回は、WEB操作を主にやってみましたが、とにかくPCスペックが低いので動作が重かったです。
いつかPC環境をよくしたいなと思っています…
おしまい。


コメント